WPAR (Workload Partition)
Workload Partitions (WPARs) are virtualized operating system environments that are created within a single AIX image. WPAR has its own private execution environment with its own filesystems and network addresses, but they still run inside the global environment. The global environment (the actual LPAR) owns all the physical resources of the Logical partition. (WPAR on AIX is like Docker and other container technology on Linux, or Zones on Solaris.)
To create a WPAR bos.wpars package needs to be installed on a minimum AIX 7.1 server. WPAR creation time takes few minutes, output will show additional filesystems have been created automatically and about 300 AIX packages (filesets) are installed in the new environment.
Global environment
This term refers to the LPARs with the AIX operating system that hosts WPARs. This environment is the classical AIX environment. The global environment has visibility into the WPARs, and can see all processes running inside a specific WPAR. WPARs can be created only in the global environment.
--------------------------------------
System WPARs and Application WPARs
Based on the command to create WPARs we can differentiate between System WPARs (mkwpar) and Application WPARs (wparexec)
System WPAR (mkwpar)
System WPARs are virtual AIX environments with their own private file systems, users and groups, login and network configurations. Most traditional system services (like cron, inetd …) are virtualized at the WPAR level, and they can be independently used within each WPAR. Each system WPAR has dedicated writable file systems, although it can share the global environment /usr and /opt file systems in read-only mode. When a system WPAR is started, an init process is created for it, which in turn spawns other processes and daemons
System WPARs are created with the command "mkwpar" and based on the flag we use, following System WPARs can be differentiated:
- shared system WPAR: (default) /usr and /opt is shared in read-only mode from the global environment
- non-shared system WPAR: (also called private or detached WPAR) it has private and writable versions of /usr and /opt file systems
- rootvg WPAR: it is created with its own rootvg on a given disk, it can be shared or non-shared
- system copy WPAR: content of filesystems of global environment are copied over to the WPAR, it can be shared or non-shared
- versioned WPAR: different AIX version (AIX 5.2 or 5.3) runtime environment than the global environment, always non-shared
Application WPAR (wparexec)
Application WPARs provide an environment for application isolation. Application WPARs have less usage on system resources than system WPARs and they don't have their own system services (cron, inetd…). It is suitable for execution of one or more processes that can be started from a single command.
--------------------------------------
Shared and non-shared system WPARs (mkwpar … and mkwpar -l …)
By default, a system WPAR shares the /usr file system and the /opt file systems from the global environment using read-only mounts. You can configure WPARs to have non-shared, writable /usr and /opt file system with mkwpar -l.
If you create a non-shared system WPAR, all files from the /usr file system and the /opt file system in the global environment are copied to the WPAR. The administrator must allocate enough space in the WPAR file systems for the files. System software in non-shared system WPARs must be kept at the same system level as the global environment in order to avoid unexpected results.
In the global environment the /wpars directory is used for filesystems of the WPARs. For example, users in a WPAR called wpar1, would see the /wpars/wpar1/usr directory as the /usr directory.
The file system configuration for a WPAR is specified when the WPAR is created. You can either use the system defaults or customize each file system. Some of the file systems in a system WPAR are local to the partition while others can be shared with the global environment.
/ , /tmp, /var, /home JFS2 file systems are created with inline logs and populated similar to a stand-alone AIX system. /usr and /opt JFS2 file systems are shared from the global environment using namefs mounts with read-only permissions. /proc is also shared from global environment, but with read-write permissions.

For shared system WPARs, all changes within the /usr and the /opt file systems are immediately visible within the WPAR. You can configure WPARs to have non-shared, writable /usr and /opt file system (mkwpar -l), which makes application installation simpler. Detached WPARs (non-shared /usr) provide improved flexibility by allowing the installation of different software in a WPAR than existing software in a shared WPAR environment. When it is necessary to have detached WPARs, you can use the syncwpar and inuwpar commands to manage the system software in detached WPARs and recover from situations where the WPAR has become incompatible with the global environment.
When a private WPAR is created, the complete /opt and /usr filesystems are copied to the WPAR's own filesystems. Although there are scenarios where keeping private copies of these filesystems are beneficial, in some cases this would be unnecessary.
For example, if our application writes only one directory under /opt (like /opt/ibm/wlp), then it is not needed to have write permisions for the full /opt (and copy the whole content of that), just only this one directory. To achieve this, we create a mount point (mkdir -p /opt/ibm/wlp), then during creation of a shared WPAR we use the -M option to tell which filesystem to export to the wpar:
mkwpar -M directory=/opt/ibm vfs=jfs2 size=2G -r -n toyman -N address=9.3.63.36 broadcast=9.3.63.255
If a WPAR is configured to have writable, non-shared /usr and /opt filesystems, the AIX system software within that WPAR cannot be directly managed from within the WPAR. Operations that are prevented on system software include apply, commit, deinstall, and reject. If it is necessary to modify system software within a non-shared WPAR, use the /usr/sbin/swvpdmgr -w <fileset_names> command to allow those file sets to be directly managed within the workload partition.
Each WPAR has an isolated network environment with unique IP addresses and a unique hostname. You can access WPARs through standard networking programs, such as telnet, ftp, and rlogin (d
Simple WPAR creation:
1. add an entry for the new system WPAR to the /etc/hosts file on the server. (test it with host <wparname>)
2a. create a shared WPAR: mkwpar -n WPARname
2b. create a non-shared WPAR: mkwpar -n WPARname -l
--------------------------------------
Rootvg WPAR (mkwpar -D devname=hdiskX rootvg=yes …)
A system WPAR which is configured with its own root volume group on a disk is called a rootvg WPAR. rootvg WPAR gives complete control over managing the storage devices exported to the WPAR, the volume groups on those devices, and the logical volumes and file systems within those volume groups. A system WPAR which is not a rootvg WPAR does not have its own root volume group, but has file systems created in logical volumes created out of the root volume group of the global system.
For a rootvg WPAR, storage devices must be exported (or allocated) to the WPAR when it is created. After it has been created, the chwpar command can be used to allocate additional disks to the WPARs root volume group or, if it contains multiple disks, to deallocate a disk. It is not possible to change a WPAR into a rootvg WPAR after it has been created.
When a system WPAR is created with its own root volume group by using the command mkwpar -D devname=hdiskX rootvg=yes … command, the root file systems are created in a separate volume group that is owned and managed by the WPAR. Rootvg system WPARs can be either a detached system rootvg (non-shared /usr) or a shared system rootvg.
A detached (private copy of /usr and /opt) system rootvg WPAR is created with the mkwpar command with the “-l” flag like:
mkwpar -n wparm91 -D devname=hdisk4 rootvg=yes -D devname=hdisk0 -N interface=en0 address=172.16.20.90 netmask=255.255.252 .0 -I rtdest=0 rtgateway=172.16.20.1
---------------------------------------
System copy WPAR (mkwpar -t …)
A system copy WPAR is created by copying the files from the root volume group of an existing AIX system or an AIX system backup image. A system copy WPAR contains configured files and file systems directly from its source. A system copy WPAR differs from a standard system WPAR because it contains the files and file systems from the root volume group of the source system. A standard WPAR is created as a newly installed system by installing a new and unconfigured environment.
The /usr and /opt file systems from the global system are not copied if the WPAR is created as a shared WPAR. If the WPAR is created with the -l option (or if the privateusr=yes attribute is set in the
general stanza of a WPAR specification file), the /usr and /opt file systems are copied into the WPAR. Otherwise, the WPAR mounts the /usr and /opt file systems in read-only mode from the global
system. A system copy WPAR can be created as a rootvg WPAR.
Creating a system copy WPAR from a system backup image: mkwpar -t -B <mksysb_image> -n <WPARname>
Creating a system copy WPAR from the running system: mkwpar -t [-l] -n <WPARname>
(It is also possible to set the general attribute system_copy to yes in a WPAR specification file: system_copy=yes)
---------------------------------
Versioned WPAR (mkwpar -C …)
A versioned WPAR has a runtime environment from an older AIX mksysb backup image and runs on a global system with a newer level of AIX. The AIX commands and libraries inside the WPAR support the older AIX level's syntax, even though the AIX kernel on the system is running a newer level. Applications that have not been certified on newer versions of AIX, can use the versioned WPAR commands and libraries (like AIX 5.2 and 5.3) on top of an AIX 7.1 kernel.
A versioned WPAR is always a system WPAR and is not shared. Versioned WPARs own writable /opt and /usr file systems.
A versioned WPAR provides a different version runtime environment than the global system. To see the files within a versioned WPAR that are replaced by local or alternative programs, run the following command within the versioned WPAR: ODMDIR=/usr/lib/objrepos odmget file_overlay | awk ’$1=="path" {print $3}’
If you have AIX 5.2 Workload Partitions for AIX 7 run the following command: ODMDIR=/usr/lib/objrepos odmget overlay | awk ’$1=="path" {print $3}’
Creating a versioned WPAR:
1. create a mksysb image of an AIX 5.2 (TL10 SP8) or an AIX 5.3 (TL 12) system that provides the content for your versioned WPAR: mksysb -i /mksysb_images/backupname
2. copy mksysb to target AIX 7.1 or 7.2 server, and update there /etc/hosts with the name of new versioned WPAR (FQDN and alias), check with host command (host <wparname>)
3. install vwpar.image package on target server, like: installp -qaXYd installation_device vwpar.images vwpar.sysmgt
4. create version wpar: mkwpar -n WPARname -C -B /mksysb_images/backupname
The remainder of the installation is similar to that of the creating a new WPAR, except that it will use the AIX 5.2 system image as the basis, installing the system packages for AIX 5.2.
---------------------------------
Application WPAR (wparexec)
Application workload partitions (WPARs) provide an environment for isolation of applications and their resources. Application WPARs have less usage on system resources than system WPARs, they do not require their own instance of system services.
Application WPARs share the filesystems of the global environment. When an application WPAR is created, it has access to all mounts available to the global environment's file system. If additional dependencies are required, you can customize the WPAR during creation using the wparexec command with the -M option
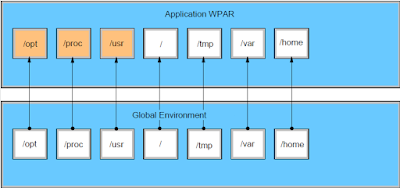
Application WPARs are created with the wparexec command. You must supply the path to the application or command that you want to create an application WPAR for, and you must supply any command line arguments when you run the wparexec command. The application can either come from a specification file, or be specified on the command line. Unlike system WPARs, it is not necessary to assign an explicit name to an application WPAR. Although both WPAR types require a name, the names for application WPARs are generated based on the name of the application running in the WPAR.
Creation of an application WPAR (as root in the global environment):
wparexec -n wparname -- /usr/bin/ps -ef > /ps.out
Application WPARs start as soon as the wparexec command is issued, and stop as soon as the application completes its operation. When the operation is complete, the configuration for the application WPAR is destroyed.
--------------------------------------
Devices
The support of devices in the WPAR is limited to fiber-attached storage devices, fiber channel adapters, and vSCSI disks.
To deploy a device to a WPAR, the command mkwpar -D or chwpar -D can be used. The device in the global environment must be in the available or the defined state. One or more storage devices can be used and non-rootvg volume groups, logical volumes, and file systems can be created within the WPAR.
mkwpar -D devname=<device name> -n <wpar name> allocate a device while creating the WPAR
mkwpar -D devname=<device name> rootvg=yes -n <wpar name> allocate a device while creating a rootvg WPAR
chwpar -D devname=<device name> <wpar name> allocate a device to an existing WPAR
chwpar -K -D devname=<device name> <wpar name> deallocate a storage device from an existing WPAR
When you allocate a storage device to an active WPAR, the device is exported to the WPAR unless it was previously exported. To import the newly allocated device into the WPAR, run cfgmgr within the WPAR.
A storage device can be allocated to more than one WPAR. However, the device can be exported to only one WPAR at a time. The device is exported to the WPAR that starts first. After a device is exported to a WPAR, the extended state of the device is listed as Exported.
# lsdev -x -l hdisk1
hdisk1 Exported 01-08-02 MPIO Other DS4K Array Disk
---------------------------------
Applications and filesystems sharing
In the WPAR, /usr and /opt are mounted by default as read only filesystems, so if our application needs to touch these filesystems, some planning would be needed. I tried to collect different scenarios, when a filesystem from the global environment needs to be shared in the WPAR:
1. If application doesn't install into /usr or /opt, or touch those file systems after installation, you can install them into the WPAR as normal.
2. If application installs into /usr and /opt, but do not touch those file systems after installation, it needs to be installed into the global environment and then execute syncwpar on all "shared" WPARs (those with read-only /usr and /opt) in which you wish to execute the application.
3. If application touch files in /usr and /opt after installation then create your WPAR with private /usr and /opt (mkwpar -l) and install them inside the WPAR.
4. If application writes only to a sub-directory of /opt but you don't want a private /opt, then you can add a read-write directory to the read-only shared /opt:
# mkdir /opt/new <--in global environment create a mount point which will appear in the WPAR /opt
# crfs -v jfs2 -g rootvg -m /wpars/wpar1/opt/new -a size=10M <--create a filesystem
# mount /wpars/wpar1/opt/new <--mount it into the wpar (after in wpar we can write files in it)
5. Temporarily sharing a global file system with a WPAR (with "namefs"):
# mkdir /wpars/wpar2/bb_fs <--create /bb_fs mount point (we want to share the global /bb as /bb_fs in the WPAR)
# mount -v namefs /bb /wpars/wpar2/bb_fs <--mount "namefs" filesystem, /bb will be mounted as /bb_fs in the wpar
6. Permanently sharing a global file system with a WPAR, with auto mount (with "namefs"):
# crfs -v namefs -A yes -d /bb -m /wpars/wpar1/bb_fs -u wpar1 <--create "namefs" filesystem from the global /bb as …/bb_fs in wpar, -u (mount group) should be the name of the wpar
# mount /wpars/wpar1/bb_fs <--after mounting in the global, in the wpar it will appear as /bb_fs (read-write)
7. Sharing a filesystem across 2 WPARs (without NFS, using "namefs):
If you have a filesystem called /local and want to add this to two WPARs called wpar1 and wpar2:
# mkdir /wpars/wpar1/local
# mkdir /wpars/wpar2/local
# mount -v namefs /local /wpars/wpar1/local
# mount -v namefs /local /wpars/wpar2/local
---------------------------------
Commands:
mkwpar -n <wparname> create a shared system wpar (-A will create as autostart)
mkwpar -s -n tyrant -l -N address=9.3.63.38 create a private wpar (option -l specifies that the WPAR being created is a private WPAR)
mkwpar -n wpar3 -N interface=en0 address=172.23.74.22 netmask=255.255.248.0 create shared wpar with network details
mkwpar -n w4 -D devname=hdisk1 rootvg=yes -N interface=en0 address=172.23.74.22 netmask=255.255.248.0 -l create a non-shared rootvg wpar
lswpar lists wpar details (name, state, type…)
WPAR States:
(D) Defined it has been defined by the mkwpar command and is ready for use, but is not active (startwpar will start it)
(L) Loaded it has been configured in the kernel, but processes have not yet been started.
(A) Active it is running normally.
(F) Frozen a checkpoint operation is initiated, and the processes are quiesced, awaiting the storing phase.
(P) Paused a checkpoint or restart operation was done, and the processes of the WPAR are ready to be resumed or killed.
(N) Maintenance it has been configured in the kernel and the file systems have been mounted, but processes do not start.
(M) Moving although wpar is Active on the arrival server, on the departure server in this state until transfer is completed
(T) Transitional an administrative operation is in progress. The wpar is being created, started, stopped, configured, and so on.
(B) Broken an administrative operation failed, leaving this workload partition in an unusable state.
(E) Error an error occurred because of invalid elements such as workload partition name and flags.
lswpar -L list wpars with all details (long format): network, filesystems, resource controls…..
lswpar -R <wparname> list a wpar resource controls (CPU, Memory limits…)
startwpar -v <wparname> start a wpar (-v verbose)
stopwpar -v <wparname> stops a wpar (waits about 30 seconds), same as "shutdown" in the wpar
stopwpar -F <wparname> stops a wpar immediately (-F force)
(if halt -q is used, wpar might not stop cleanly, which leaves it in transition state.)
rmwpar <wparname> removes a wpar
clogin <wparname> login to the given wpar, it is like a console login (it is not an ssh login)
ps -ef@ wpar1 lists the processes of an wpar
lparstat -W wpar related lparstat (CPU) details
uname -n shows the name of the wpar (good way to find out where we are)
uname -W shows the id of the wpar (good way to find out where we are)
savewpar -f <file> <wparname> back up a WPAR to a file (savewpar -f /tmp/wpar1_backup.bff wpar1)
restwpar -f/dev/rmt1 creates a wpar from a wpar backup image that was created by savewpar, mkcd, or mkdvd
restwpar -s -F -f /tmp/wpar1_backup.bff -h toyman -n toyman -d /wpars/toyman -M '-N address=9.3.63.36 broadcast=9.3.63.255'
syncwpar <wparname> synchronizes the software that is installed in the global shared parts with wpar
syncwpar -A synchronize all WPARs (If you patch the global AIX level then execute syncwpar -A.)
syncwpar -D … if there are private wpars, use -D (detached wpars)
migwpar migrate a WPAR from AIX 6.1 to AIX 7.1. (or migrate a versioned WPAR from AIX 5.2)
---------------------------------
Changing a WPAR’s IP address
On the global environment:
# mkwpar -n wpar1 -N address=172.16.20.100 netmask 255.255.252.0 <--create a wpar with given IP
# chwpar -K -N address=172.16.20.100 wpar1 <--remove IP from wpar
# chwpar -N address=172.16.20.102 netmask=255.255.252.0 wpar1 <--configure new IP
There is no direct way to change the address of a system WPAR network; you must remove the old network with the chwpar -K command and add the network with the new address
---------------------------------
Configuring domain resolution for system WPARs:
You can configure the domain resolution for system WPARs using the -r flag for the mkwpar command. Files such as the /etc/resolv.conf file do not exist in system WPARs by default.
To copy the global environment's domain resolution configuration into the system WPARs, run: mkwpar -n wpar_name -r
Running this command copies the following files into the system WPARs, if they exist in the global environment:
/etc/resolv.conf
/etc/hosts
/etc/netsvc.conf
/etc/irs.conf
/etc/networks
---------------------------------
Allocate disk to a WPAR
A disk can be allocated to either an active or inactive WPAR. The chwpar syntax is the same for both scenarios.
Add a disk to a running WPAR:
Global# chwpar -D devname=hdisk2 wpar1 <---assign the disk to the WPAR
Global# clogin wpar1 <--login to the WPAR
WPAR1# cfgmgr <--in the WPAR scan for new devices
WPAR1# lspv <--list new disk
Alternatively, a disk can be allocated to a WPAR during its creation time. You must specify the -D option of the mkwpar
How to remove a disk from a WPAR
Global# chwpar -K -D devname=hdisk2 wpar1
---------------------------------
Configuring resource controls for system WPARs
You can configure the resource controls to limit the physical resources a system WPAR has access to using the -R flag for the mkwpar and chwpar commands.
To initialize resource control settings, run the following mkwpar command:
mkwpar -n wpar_name -R active=yes CPU=10%-20%,50% totalProcesses=1024
In this example, the WPAR is entitled to the following system resources:
A minimum of 10% of the global environment’s processors upon request
A maximum of 20% of the global environment’s processors when there is contention
A maximum of 50% of the global environment’s processors when there is no contention
A maximum of 1024 processes at a time
The active attribute can be set to yes or no. When the active attribute is set to no, resource controls are disabled, but the settings are maintained in the configuration database.
To change resource control settings dynamically for an existing active or inactive application WPAR run the following chwpar command:
chwpar -R totalThreads=2048 shares_memory=100 wpar_name
You can also use the -K flag for the chwpar command to remove individual attributes from the profile and restore those controls to their default, as follows:
chwpar -K -R totalProcesses shares_CPU wpar_name



















